What is Whisper from OpenAI?
Whisper is a speech recognition model (ASR – automatic speech recognition) from OpenAI. The model itself is multi-task model and as a result in addition to speech recognition, can also do language identification and speech translation across a number of languages. The model is open sourced and it comes in 5 sizes. Of these, 4 have a english-only variant which seem to perform better if one only needs english. The model is also robust to noise, accents, background noise and technical language. Whisper achieves near SOTA performance with zero-shot translation from multiple-languages to English.
Model Characteristics
The model was trained on a large corpus of data and was trained using weak supervision using large scale noise data. Of this large data corpus ~680K hours of audio and corresponding transcripts; ~438K hours (65%) of this data is english only (both audio and transcripts); ~126K hours (18%) is non-english audio and english transcripts; and finally ~117K hours (17%) is non-english audio and non-english transcripts and cover 98 languages.
The model is available in multiple sizes as called out and the table below outlines these model characteristics.
| Size | Parameters | English-only model | Multilingual-model | VRAM needed | Speed (Relative) |
|---|---|---|---|---|---|
| base | 74 m | base.en | base | ~ 1gb | 16x |
| tiny | 39 m | tiny.en | tiny | ~ 1gb | 32x |
| small | 244 m | small.en | small | ~ 2gb | 6x |
| medium | 769 m | medium.en | medium | ~ 5gb | 2x |
| large | 1.55 b | n/a | large | ~ 10gb | 1x |
Whisper does support transcription and translation across 98 language; it performs best when sticking with English. One needs to be careful when using the non-english models as the transcripts are not in the same language as the audio and can lead to hallucinations. The large model has a word error rate (WER) of 0.12 for English, 0.18 for Spanish, 0.23 for French, 0.25 for German and 0.28 for Mandarin2. However, some lower covered languages have much higher WER - e.g. Arabic (0.79), Hindi (0.86) and Swahili (1.00).
Whisper ASR Architecture
As it is typical for language based models, Whisper uses a seq-to-seq (transformer encoder-decoder) architecture, where the input is a sequence of audio frames (30 sec segment pairs) and the output is a sequence of text. Whisper is best used to transcribe “audio to text” use cases. It is not well suited for “text to audio” (i.e., TTS – text to speech) cases as it is not trained for this task. Whisper is also not trained for speech synthesis, but can be used to generate text from audio. And finally, Whisper cannot be used for real-time speech applications and is best used for batch processing.
The figure below shows the Whisper ASR architecture (image credit: OpenAI); the transformer model is training on many different speech-related tasks including speech recognition, language identification, and voice activity detection - these collectively represent the sequence of tokens for the decoder to predict and greatly simplifies things by allowing one model to replace many tradition speech processing pipelines.

What I think is really interesting about the Whisper model is that it is trained using weak supervision. OpenAI took a different approach for speech recognition and not use the typical self-supervision or self-training techniques that have been a mainstay of recent large-scale speech recognition work. I believe this is what makes the model so robust and able to handle noise, accents, background noise and technical language. OpenAI trained Whisper to predict raw text of transcripts, using the expressiveness provided by the seq-2-seq implementation to learn the mapping between utterances and their transcripts. All of this allows a simpler pipeline.
More details on the Speech Recognition model can be found in the OpenAI Whisper paper Robust Speech Recognition via Large-Scale Weak Supervision .
What is Weak Supervision?
As a side node, I am quite excited to see how OpenAI is using weak supervision to scale and getting better results. The following quote from their paper speaks for itself.
Our work suggests that simple scaling of weakly supervised pre-training has been underappreciated so far for speech recognition. We achieve these results without the need for the self-supervision or self-training techniques that have been a mainstay of recent large-scale speech recognition work.
All is well and good, but what is Weak Supervision?
As I called out in my book Practical Weak Supervision: Doing More with Less Data 📖 : Weak supervision is a broad collection of techniques in machine learning where models are trained using sources of information that are easier to provide than hand-labeled data, where this information is incomplete, inexact, or otherwise less accurate. Instead of hand-labeling high-quality data, all of which is very cost-prohibitive, we can use other techniques that combine diverse sources of data, creating an approximation of labels. Using weak supervision, we can reconcile these labels to a single label.
Weak supervision enables these noisy, weakly sourced labels to be combined programmatically to form the training data that can be used to train a model. Labels are considered “weak” because they are noisy—i.e., the data measurements that the labels represent are inaccurate and have a margin of error.
More details here:
View on Twitter
Transcription with Whisper
I figured, one of the best ways to try out the Whisper model and run it through its paces is to try a bunch of transcription - and that too on something fairly technical , where the language isn’t typical in the broader sense of spoken english. And what better way to test AI is to use something that talks about AI. To that end, I used Sam Charrington ’s popular TwimlAI podcast as the guinea pig. 😄
Now on one hand, it seems pretty easy to install Whisper (it is a pip install) and run it on a single audio file.
View on Twitter
The reality is that there are a lot of dependencies and it is not as easy as it seems.
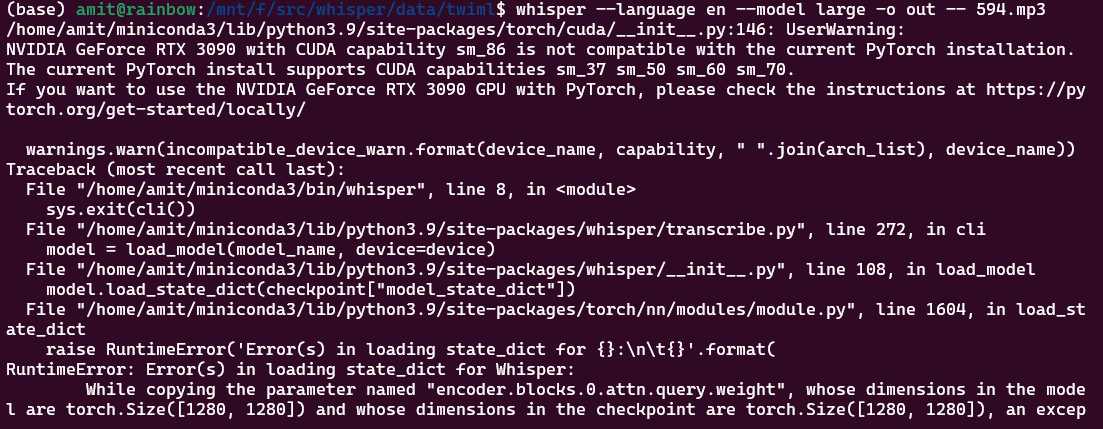
However, I did manage to resolve everything and get it working - and the results were pretty good.👍

But I wanted to see how well it would work on a large corpus of audio files. So I wrote a simple script that would download all the episodes of TwimlAI from YouTube as mp3, and then transcribe them using the Whisper model. As of writing this, there are 547 episodes of TwimlAI and all of those transcriber to my github repo here. . Each episode has three resulting files when transcribed:
- txt file - there is a text file which contains the transcript
- srt file - this is the subrip subtitle file which can be used to add subtitles to the audio file
- vtt file - this is WebVTT file (web video test to track file) and contains the transcript and the time codes that sync the captions.
You can get all the transcripts which can either be downloaded as the zip file twiml-episodes-whisper-transcribed.zip 💾 or they are also in the folder twiml-episodes-whisper-transcribed 📁 in the github repo here.
I also transcribed one file using both the To show the difference the base and the large model. You can find both versions in the folder model-comparison 📁 of one specific episode - #544 - #AI Trends 2023 - AI Trends 2023: Natural Language Proc – ChatGPT, GPT-4 and Cutting Edge Research with Sameer Singh. Not to get into all the details, but the transcription using the large model was approx 120 lines longer. The image below shows you an eagle view of the difference between the two transcriptions - there are a lot of differences in the text, and the quality is much better on the large model.

Steps to run this locally
If you want to run this locally, start by cloning the repo . It is best to use conda to get the dependencies managed. I prefer Miniconda , but you can use any conda installation. The next set of steps assumes that you have conda installed; see the docs if you need help installing.
Step 1: Create a conda environment
I am running this on Ubuntu 22.0.01 LTS (Jammy Jellyfish) and am using an NVidia RTX 3090 GPU. I am also running Python 3.8.5.
Create a conda environment and install the dependencies. I have included the environment.yml file in the repo, which you can use to create the environment. The name of the environment can be changed to anything; I use whisper in my case.
name: whisper
channels:
- pytorch
- defaults
dependencies:
- cudatoolkit=11.3
- git
- numpy=1.22.3
- pip=20.3
- python=3.8.5
- pytorch=1.11.0
- scikit-image=0.19.2
- torchvision=0.12.0
- pip:
- -r requirements.txtOnce conda is installed, you run the following command to create the environment:
conda env create -f environment.yaml
And you would sees something like this as the output:
Step 2: Activate the environment
If the whisper environment if not already active, can be activate it by running the following command:
conda activate whisperStep 3: Install the Whisper model
The next step is to install the Whisper model in the environment. This is a pip install , and you can run the following command to install it:
pip install git+https://github.com/openai/whisper.git The output should look something like this - note the exact details most likely will be different.
Step 4: Download the TwimlAI episodes
The next step is to download the TwimlAI episodes. I have written a python program to do this. This downloads the episodes from YouTube and saves them as mp3 files. You can download all the episodes, or a single one. I also had to update this to use a local file to get around some issues that PyTube was having. You can find the program in the download_episodes.py file in the repo. You can run the program by running the following command:
python ./download_episodes.pyYou will see the following output:

I would suggest using Option 4 - Using a local playlist. The file twiml-episodes.txt 🗒️already contains the list of all the episodes. By default the episodes will be downloaded as mp3’s into a folder called twiml-episodes 📁. You can change the folder name by editing the download_episodes.py file.
Here is the code snippet that downloads the episodes:
# Download all the videos from the local playlist text and save it as a mp3 file
def downloadVideoFromLocalPlaylist(playlist_name, mp3_path):
with open(playlist_name, 'r', encoding="utf8") as f:
reader = csv.reader(f, delimiter='|')
index = 1
fileSaved = 0
for row in reader:
# following is used to skip over episodes that have already been downloaded
# if index < 526:
# print("Skiping ... # " + str(index))
# index += 1
# continue
# print("Episode: " + row[0], "Title:" + row[1], "URL:" + row[2])
episode = row[0]
title = row[1]
url = row[2]
print("\nDownloading Episode #" + episode + " ... " + title)
try:
tempFileName = validFilename(str(index) + '_' + title + ".mp3")
downloadVideo(url, mp3_path, tempFileName)
fileSaved += 1
except IOError:
print(f"{textColors.FAIL}Error: can\'t save the following file. Most likely it has an invalid character in the name.{textColors.RESET}")
print("File: " + tempFileName)
except VideoUnavailable:
print("{textColors.FAIL}Video: " + tempFileName + " is unavailable, skipping.{textColors.RESET}")
except:
print("{textColors.FAIL}Unexpected error: " + sys.exc_info()[0] + "{textColors.RESET}")
print("Download complete. Number of episodes saved: " + str(fileSaved))
index += 1
# download mp3 from youtube
def downloadVideo(video_url, mp3_location, filenametoSave):
yt = YouTube(video_url)
yt.register_on_progress_callback(fancy_progress_bar)
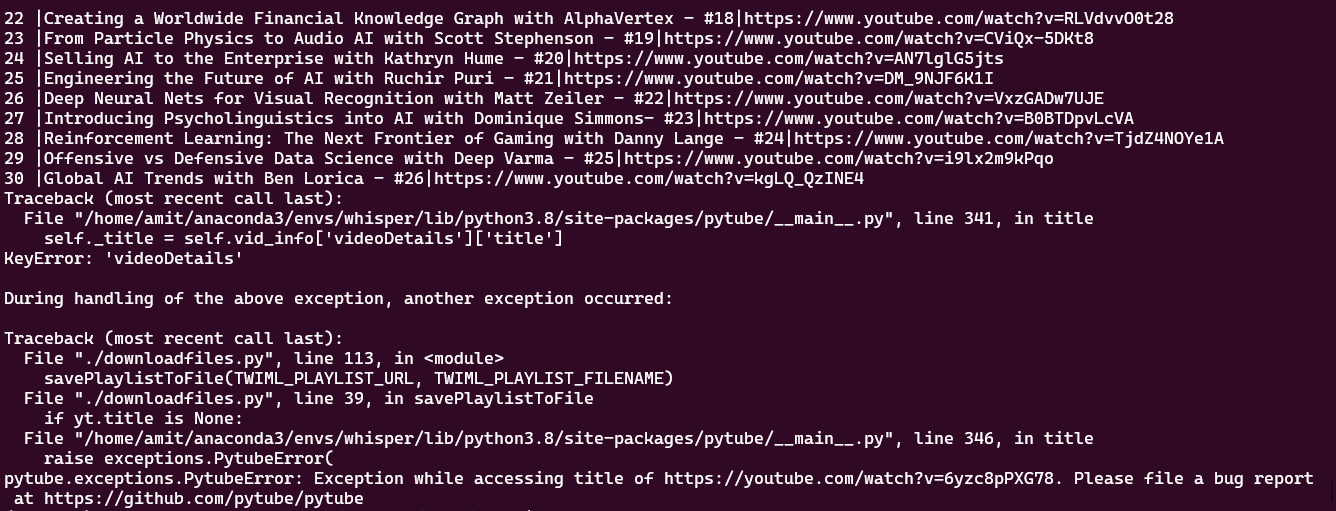
yt.streams.filter(only_audio=True).first().download(output_path=mp3_location,filename=filenametoSave)The reason the options fail randomly is because of a change that YouTube made. At the time of this post, the way they render the page breaks things and one cannot get the title. You will see an error related to the video title not being found.
Step 5: Running transcription
Finally you can transcribe the episodes. The transcribe.sh file in the repo contains the code to do this and it simply loops over the twiml-episodes folder and one-by-one processes the mp3 files. The output is saved in the out folder 📁. The shell script is as follows:
for f in twiml-episodes/*.mp3 ; do whisper --language en --model base -o out -- $f; doneHere is what the transcription looks like when it is running:
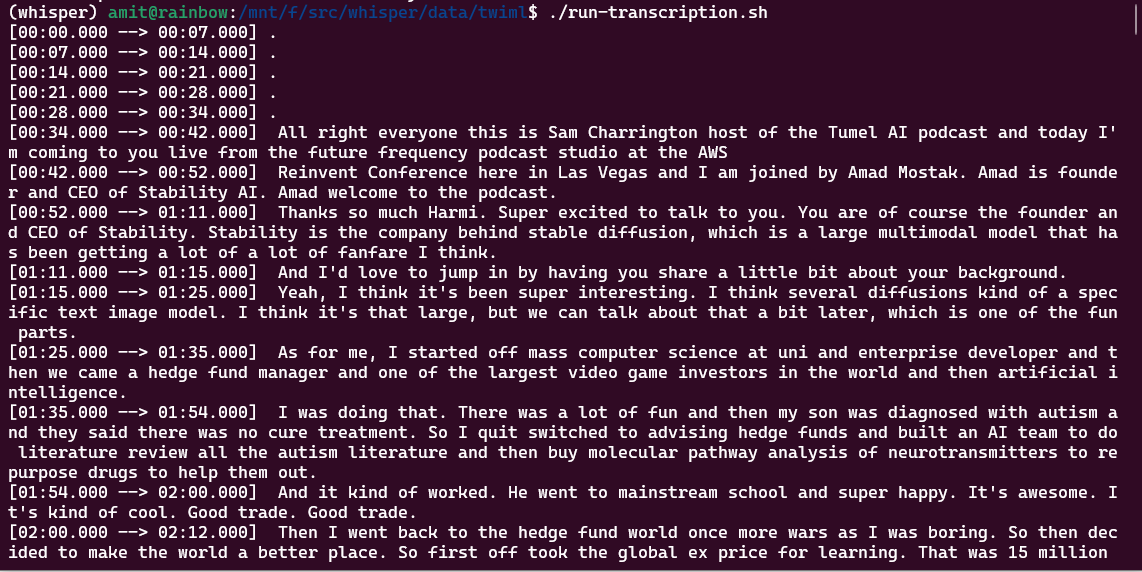
You can also run this only on a subset or one file to transcribe - as shown below. Also if the model isn’t already downloaded, it will download it first.

Of course you can update the folders, etc to match what you needs are.
GPU Profile
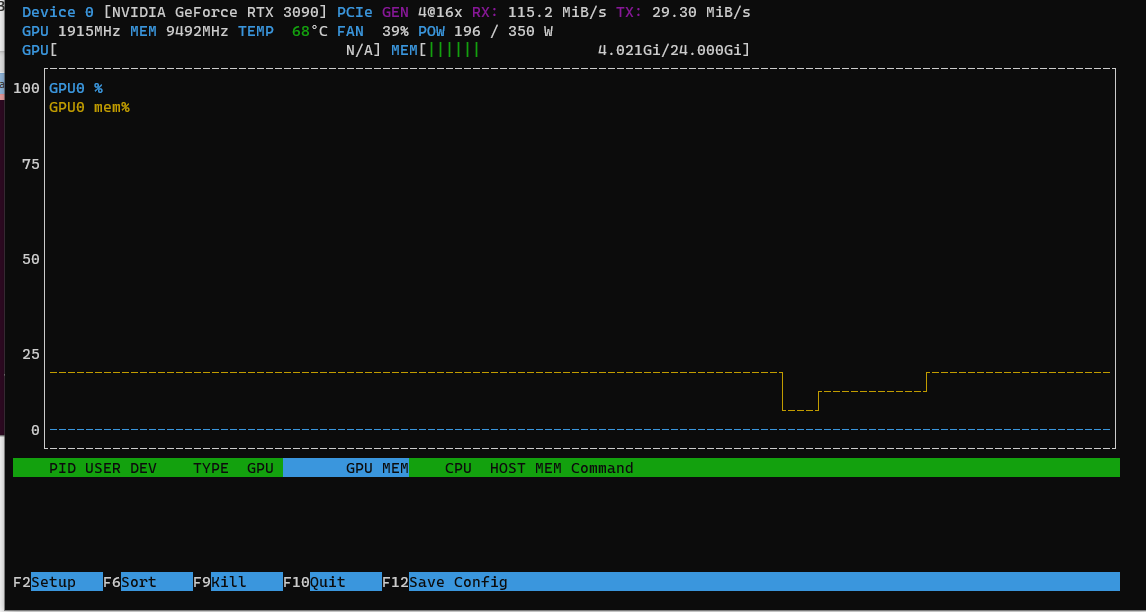
I also wanted to show the GPU profile when inferencing between the base and the large models. The image below shows the GPU profile when running the base model. You can see that the GPU is being used at 100% and the memory is being used at ~4gb and ~200W of power. The time to transcribe each episode isn’t too long as well - around 2 minutes.
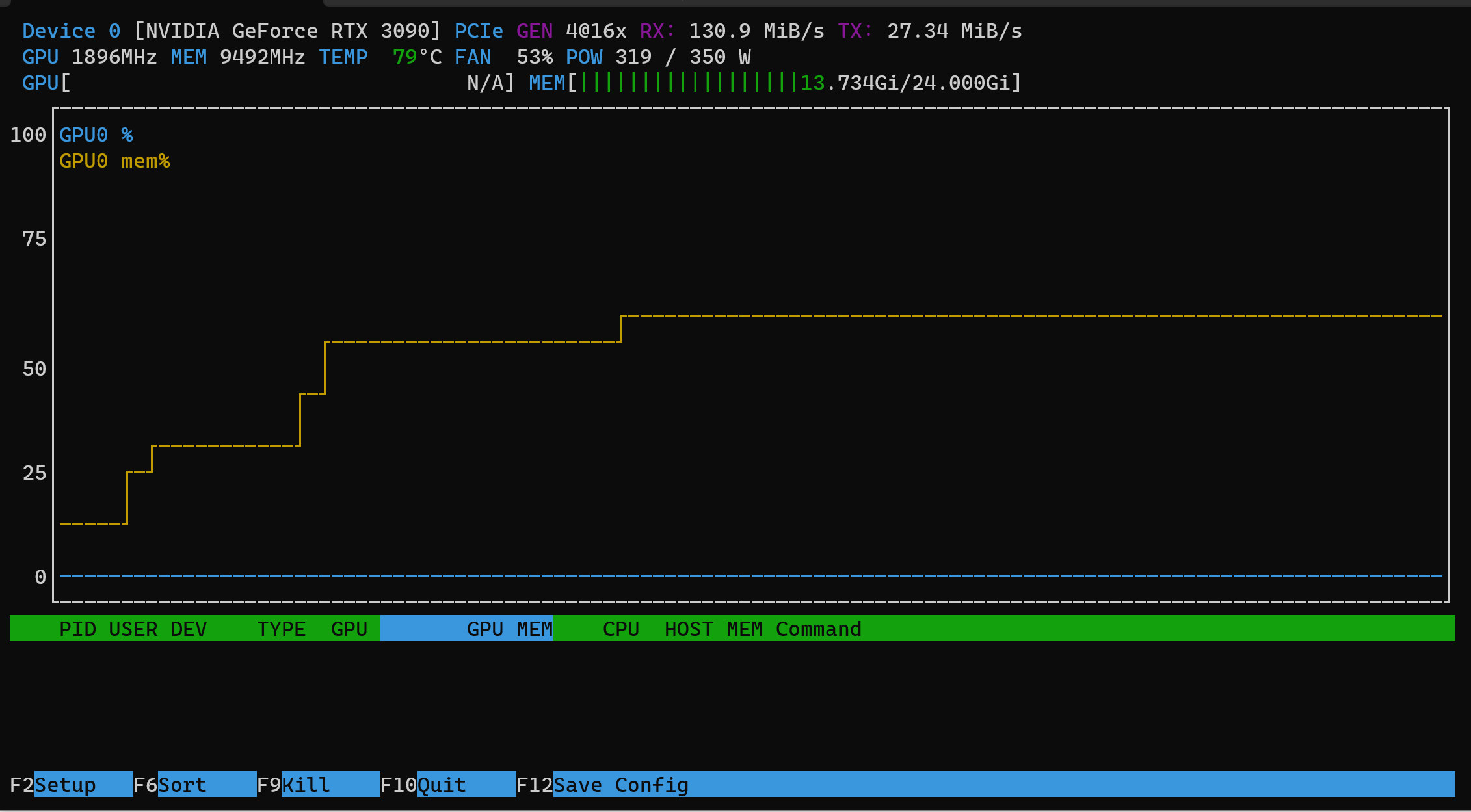
The image below shows the GPU profile when running the large model. You can see that the GPU is being used at 100% and the memory is being used at ~14gb and ~320W of power. The time to transcribe each episode is much longer - around 10 minutes.
In conclusion, this was a fun little thing to work on; I had done this a few months ago but not had the time until now to blog it. I also transcribed the episodes using our Azure Speech service which I think is more robust and scalable in many ways (but then I am a little biased 💜). I will blog about that in the future and we can compare.