Reinforcement Learning is teaching by example – it is how most of us learn. Reinforcement Learning (#RL) is a different approach to ML – it is a set of techniques that allows AI algorithms to experiment and learn from experience. RL falls in between supervised and unsupervised learning – there isn’t any labeled data, but at the same time it isn’t unsupervised either. At its most simple form, RL is a computational approach for automating goal-oriented decision making and learning.
Inherent RL is the ability to operate in a dynamic uncertain environment. RL can be more formally defined as the study, science, and problem of intelligence in the form of an agent that interacts in an environment. At the end of the day, almost all RL problems can be formalized as MDP ( Markov decision processes ).
The problem is represented by an environment – such as a world where an agent is based in. The steps in RL are quite clear – the agent takes actions, that have some effect on the environment. The environment acts on those actions and gives back an observation to the agent – what it sees and senses.
One special signal the environment gives back to the agent is called a reward signal. This signal is what an agent used to figure out how well it is doing. The RL problem is to take actions over time, to maximize the reward signals. And this notion of maximizing is what the agent is learning from the environment, without any explicit supervision. This construct helps an agent achieve a goal, even in an uncertain environment, factoring in delayed and indirect consequences of actions.
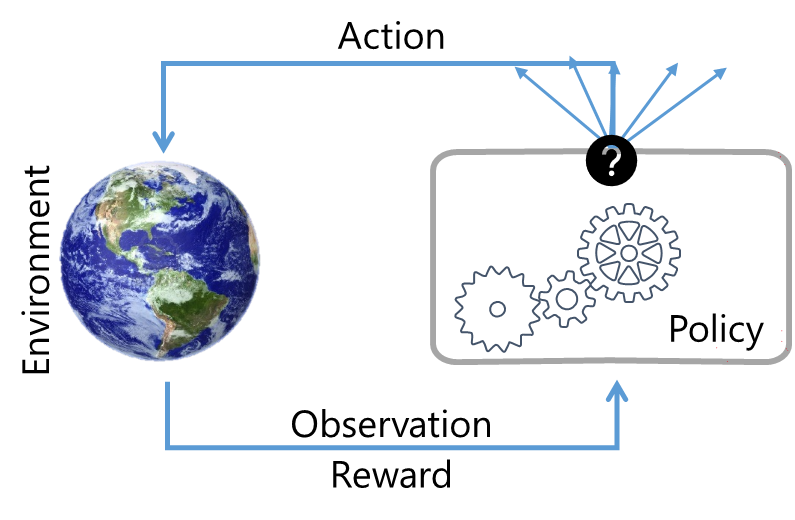
Reinforcement Learning Overview
An agent can have many actions (i.e., choices); it uses a ‘reward’ signal to determine which of those actions is considered ‘good’ vs. ‘bad’. Of course, this determination is in the context of the outcome that we want to achieve.
Some examples of rewards in different industries and use cases:
- Maneuvering a UAV’s – positive for following a chosen trajectory; negative for deviating from that trajectory.
- Managing an investment portfolio – positive for each dollar earned; negative for each dollar lost.
- Controlling a power station – As one can imagine, this control would typically constitute a few things in the environment – a sequence of controls, motors, batteries, power sources, etc. In optimizing the throughput of a power station, we can think of positive rewards for producing power; negative for exceeding a safety threshold.
- Playing a game – positive for increasing score; negative for decreasing score.
Core concepts that make up RL:
Agent – The ‘thing’ that is using and acting on behalf of a user or another program. This can be a program executing a business process, a embedded process, the arm of a robot, actuators on a self-driving car controlling the wheels, etc.
Policy – A policy outlines how an agent would behave at certain times and can be thought of as the problem we are trying to solve. This is an agent’s behavior function and is a mapping of the business outcome that we are after.
Reward – A reward is a feedback special signal and outlines what is considered good (or bad) and is correlated with the agents’ current action, and the current state of the environment. All goals can be described as to maximize the cumulative reward. The reward is not a binary number but is a scaler between 0 and 1 – with zero being ‘bad’ and one being the best reward attainable for that action.
Value function – A value function represents how good is it to be in a particular state and related actions. Where a reward signal is showing the specification of good in an immediate sense (current step), the value function is representing the notion of good overall. At an abstract level, when thinking about the prediction of rewards, a rewards function is the primary, we can think of value functions as the secondary. In the end, we are more concerned with getting higher-value functions to make decisions, and not as much as higher rewards.
Model – A model is an agent’s view of the environment and mimics its behavior. This allows us to make inferences on how the environment will behave and is often used for planning. Think of the model as the strategy to use in solving the problem at hand.
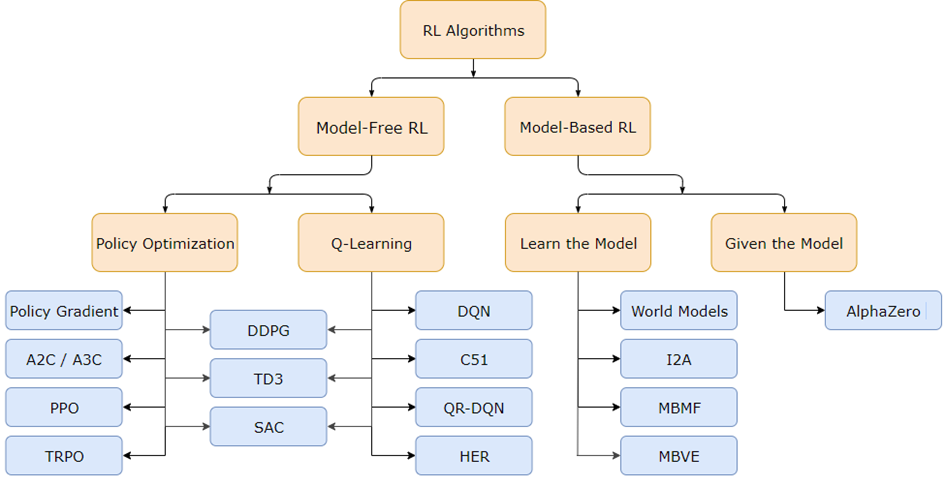
Taxonomy of RL Algorithms
There are many types of RL algorithms (as we can see in the figure below), but these can broadly be classified in the following two categories.
- Model free: A model-free algorithm can be thought of as an explicit trial and error algorithm. In a model free approach, the agent doesn’t have or ignores the environment; instead, the agent uses experience and tries to optimize a Policy.
- Model based: On the other hand, a model-based algorithm reflects how an environment works, and factors that the associated reward functions and tries to maximize that. Technically, this is the optimization of the transition probability distribution of the MDP.
The main difference between the two - in one the algorithm optimizes for the environment, and in the other for a policy gradient. There is no one right or wrong algorithm - a lot of it depends on the situation at hand and what one is trying to optimize for.
As we can see below each of these categories can be further broken down - we won’t go into the details of those quite yet, maybe that is for another post. One of the most important components of most RL algorithms is a method to efficiently estimate values - at the end of the day, this is all about value estimation.
Exploration and Exploitation
There are two concepts of exploration, and exploitation which are at odds with each other and for a given situation, we should aim to get a balance of some sorts. In simple terms, RL is sequential decision making - one selects actions to maximize future rewards, and we need to plan long term - rewards might be delayed and not immediate, and we cannot be greedy. Sometimes, we need to sacrifice the immediate reward to gain more (or better) longer term rewards.
This can be thought of trial-and-error learning loop - with the stream of experiences that constitute loops of actions, rewards, and observation. At the end of the day, this loop is what matters.
Exploration finds more information about the environment, and in doing so gives up rewards. Exploitation on the other hand, exploits the information it already has to maximize rewards. If we don’t exploit, we might be stuck in a sub-optimal place, and how would be know if there is a better sense or rewards without trying?
When we are in the trial-and-error loop we might be losing rewards, and the agent needs to discover a good policy to maximize the rewards - this is the tension at the opposite ends of a string pulling each other.
It is important to balance both exploring and exploiting.