Floating point calculations are slow for computers (specifically CPUs); possibly representing the same struggle for many humans. :)
I remember a time when a FPU (floating point unit) was an upgrade and one had to pay extra to get one. Very useful when you needed that extra precision in computing - and in my head, it always seemed like the Turbo button. :)
For most #ML workloads and computations, precision isn’t the most important criteria; with every increasing data and parameters (looking at you GPT-3 with 45 TB of data and 175 billion parameters!), what most ML needs today is speed and dynamic range.
This is where bfloat16 (Brain floating-point format with 16 bits) - a new floating-point format comes handy and in the context of #AI improves on IEEE 754 - the current floating-point arithmetic standard.
As per IEEE 754, a floating point it will always take up 32 bits (see Figure 1 below) - irrespective of the size of the number. The exponent (8 bits) tells us how many numbers we shift (left or right) and place the decimal. The fraction (23 bits), also called the mantissa, holds the actual number - i.e. the data.

bfloat16 truncates the data size in a third (see Figure 2) - with the fraction truncated from 23 to 7 bits. This of course means bfloat16 isn’t as precise. However bfloat16 has the same exponent bits as IEEE-754 it can represent a similar range (small to large), but more importantly are easier to convert between bfloat16 and IEEE 754.
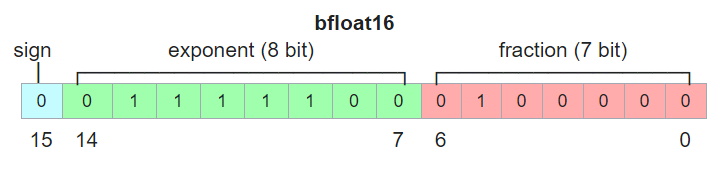
Less precision doesn’t impact the matrix multiplication as much so in the context of ML training and inference these chips at scale are more efficient - not only they are faster, they also use less power, and memory bandwidth.
What is interesting in some neural nets such as a DNN, these less precision bfloat16 are more precise compared to IEEE 754! This is because the regularization and quantization weights cannot use the finer precision represented by IEEE 754 but adapt better with bfloat16. :)
Finally, bfloat16 is not a universal standard (yet); most AI chips support this. ARM, Intel, and, AMD have started adding support for this in their chipsets.